Best Open Source LLMs in 2026: Ranked and Compared
Something happened in April 2026 that would have seemed implausible two years ago: an open-weight model topped SWE-Bench Pro ahead of GPT-5.4 and Claude Opus. That model was GLM-5.1, from Zhipu AI. The closed frontier, once comfortably ahead on every meaningful coding benchmark, had been overtaken by a model you can download and run on your own infrastructure.
That’s the landscape right now. The question has shifted from “can we get away with open source?” to “which open-weight model do we standardize on and why?”
This post answers that. It’s grounded in what the technical papers and independent benchmarks actually say, not vendor announcements. Where numbers are vendor-reported rather than independently verified, I’ll tell you.
Table of Contents
Why 2026 Is a Different Moment for Open Source
The gap between open-weight and closed-source models narrowed to roughly 6-9 months on most capability benchmarks by mid-2026. That matters in practice for three reasons.
First, data control. When you run a model on your own infrastructure, your code and customer data never touch a third-party API. For healthcare, finance, and any company under GDPR or regional data-residency rules, this isn’t optional. Second, cost at scale. A team running 100,000 requests a day through a major closed API can easily spend $30,000-$50,000 a month. Self-hosting a comparable open model on four A100 GPUs runs roughly $8,000-$12,000 per month on cloud compute — and that cost is fixed regardless of volume. Third, customization: you own the weights, which means you can fine-tune, distill, or modify behavior in ways no commercial API allows.
Before choosing a model, it’s worth understanding how these systems work at a base level. The how large language models work post covers the transformer architecture, pre-training, and fine-tuning — the groundwork that makes sense of everything below.
The Architecture Shift You Need to Understand First
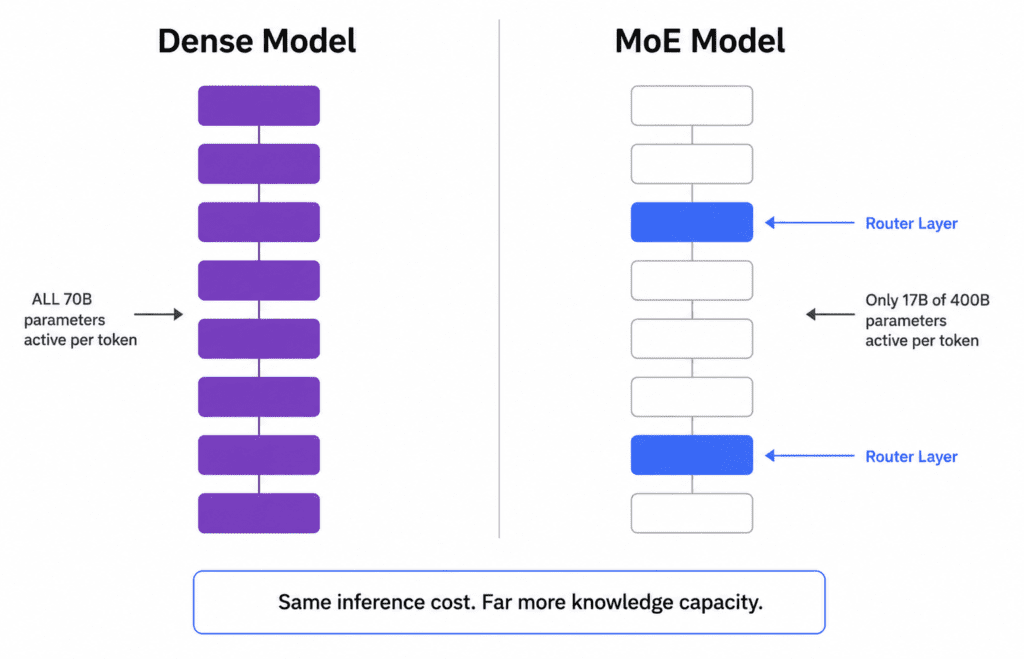
Every frontier open-weight model in 2026 uses Mixture-of-Experts (MoE) architecture. Understanding what that means practically is the difference between reading benchmarks correctly and being misled by them.
A traditional dense model activates all of its parameters on every token it processes. If a model has 70 billion parameters, all 70 billion do work on every single word. MoE models have a different design: a routing layer sends each token to a small subset of specialized “expert” sub-networks, leaving the rest idle. The result is that a model can have 400 billion total parameters on disk but only activate 17 billion per token during inference.
Why does this matter for you? Because inference cost — the compute you actually pay for or provision — is determined by active parameters, not total parameters. A 400B MoE model that activates 17B per token costs roughly the same to run as a 17B dense model, while carrying the knowledge capacity of something much larger.
This is why the spec sheet can be misleading. When you see “400B parameters,” the first question should be: how many are active? That’s the number that determines your hardware requirements and inference speed.
What the Benchmarks Actually Measure (and What They Miss)
Most LLM comparison posts lead with MMLU scores. MMLU is a multiple-choice test across academic subjects. It was a useful signal in 2022. In 2026, it’s been trained on so extensively that a high MMLU score tells you very little about real-world usefulness.
The benchmarks that carry more weight right now:
SWE-Bench Verified and SWE-Bench Pro measure the model’s ability to solve real GitHub issues — actual software engineering, not multiple choice. GLM-5.1 leads SWE-Bench Pro at 58.4%, surpassing GPT-5.4. Qwen 3.6’s 35B MoE variant hits 73.4% on SWE-Bench Verified.
Artificial Analysis Intelligence Index is a composite of 10 independent evaluations — GDPval-AA, τ²-Bench, Humanity’s Last Exam, GPQA Diamond, and others. It’s currently one of the more trustworthy neutral assessments because no lab controls the weighting.
GDPval-AA measures agentic real-world task completion, not language modeling quality. DeepSeek V4 Pro leads here among open weights.
When a vendor publishes a number without specifying the benchmark and whether it was independently verified, treat it with appropriate skepticism.
The Models That Actually Matter Right Now
Llama 4 (Meta) — Best Ecosystem and Long-Context Handling
Meta released Llama 4 in April 2025. The entire family uses MoE, which was the biggest architectural change from Llama 3. Llama 4 Scout has 17 billion active parameters out of 109 billion total, uses 16 experts, and fits on a single H100 GPU. Llama 4 Maverick has the same 17 billion active parameters but 128 experts and 400 billion total parameters stored, running on a single DGX host.
What Llama 4 actually introduces architecturally that’s worth understanding: early fusion multimodality, meaning image and text tokens are processed together from the start rather than images being bolted on afterward. And iRoPE — interleaved Rotary Position Embeddings without the position-embedding layers in some attention heads — which is what enables the extreme context lengths. Scout officially supports a 10-million-token context window, the longest among publicly available open-weight models as of writing.
The honest caveat on Llama: the licensing is not Apache 2.0. The Llama 4 Community License has usage restrictions. If you’re building a product that could exceed a certain user threshold, or operating in specific regions, the license requires you to apply to Meta. For many teams, that’s fine. For teams that need clear commercial rights from day one, it’s a friction point worth checking before you build a stack around it.
Where Llama 4 genuinely wins is ecosystem. More inference frameworks, more fine-tuning guides, more community quantized models, and more tutorials than any other open-weight family. If you value being able to Google a problem and find an answer, Llama 4 is still the default starting point.
Qwen 3 and Qwen 3.6 (Alibaba) — Best All-Round and Strongest Multilingual
The Qwen3 Technical Report (arXiv:2505.09388) lays out the architecture and training process in full. Qwen3 covers both dense models (from 0.6B to 32B parameters) and MoE models, with the flagship MoE sitting at 235 billion total parameters with 22 billion active per token. All models were pre-trained on 36 trillion tokens across 119 languages — an expansion from Qwen2.5’s 29 languages.
One innovation the paper covers in detail is the thinking budget mechanism. Qwen3 integrates two operating modes into a single model: a thinking mode that runs extended chain-of-thought reasoning for complex tasks, and a non-thinking mode that gives fast direct responses. Users can allocate computation dynamically — you don’t need separate model deployments for “smart” and “fast” tasks. The paper documents that this was achieved through a four-stage post-training process: two stages focused on building reasoning through reinforcement learning and long chain-of-thought fine-tuning, followed by two stages that blend reasoning and non-reasoning data and apply general-domain reinforcement learning.
By April 2026, Alibaba released the Qwen 3.6 generation: the Qwen3.6-35B-A3B is a sparse MoE with 35 billion total parameters but only 3 billion active per token — which means inference costs closer to a 3B dense model with capacity well above it. The benchmark SWE-Bench Verified number (73.4%) is vendor-reported, worth noting.
The licensing story here is clean. Qwen3 and Qwen 3.6 open-weight models are Apache 2.0. You can use them commercially, fine-tune, modify, and distribute without restriction or royalties. For teams building products on top of open models, this is the safest legal footing in the space.
Mistral Small 4 — Best for European Compliance and Production Efficiency
Mistral AI released Mistral Small 4 on March 16, 2026. The architecture is 119 billion total parameters, 128 experts, 4 active per token — which means only 6 billion parameters (8 billion including embedding and output layers) fire per inference pass. The practical result: compared to Mistral Small 3, Small 4 delivers 40% lower latency and three times the throughput on equivalent hardware.
What’s architecturally notable is configurable reasoning depth per request. Rather than running fixed computation on every query, Small 4 lets you set how hard the model should think on a per-request basis. A quick factual lookup uses less compute than a multi-step reasoning task. This is one of the few models where that capability is built into the architecture rather than requiring separate model deployments.
Mistral Small 4 is Apache 2.0, multimodal (text and image), with a 256,000-token context window. The company is based in Paris, which matters for teams operating under GDPR: you can self-host a European model on European infrastructure and keep data fully regional.
The trade-off is benchmark position. On the Artificial Analysis composite index, Mistral Small 4 scores well below the Kimi/DeepSeek/GLM tier. It’s not the strongest model if raw benchmark performance is your primary constraint. It is a strong model if predictable licensing, European jurisdiction, and production efficiency are your primary constraints.
DeepSeek V4 Pro — Best for Reasoning per Dollar
DeepSeek V4 Pro is, by the neutral Artificial Analysis composite, the strongest agentic reasoning model among open weights. It scores 52 on the AI Index (compared to Kimi K2.6 at 54), leads the GDPval-AA agentic leaderboard among open weights, and is released under the MIT license — the most permissive option in the space.
The model is 1.6 trillion total parameters with 49 billion active per token (MoE). The main practical constraint is hardware: running it at full precision requires significant GPU resources. In production, most teams access it via hosted API rather than self-hosting.
Worth knowing honestly: DeepSeek is a Chinese lab, which creates policy risk for some teams and sectors regardless of the technical quality. Organizations in defense-adjacent industries, or operating under certain US government contracts, may face restrictions independent of the model’s capabilities.
The Licensing Issue Nobody Talks About Enough
“Open source” means different things in the LLM space. Understanding the difference before you build matters more than the benchmark position.
Apache 2.0 and MIT are the permissive end: commercial use without restriction, modification, fine-tuning, distribution. You own whatever you build. Qwen 3/3.6, DeepSeek, GLM-5.1, and Mistral Small 4 are all in this category.
Llama’s community license is the most nuanced. You can use the models commercially in most cases. But the license includes usage thresholds (you may need to request permission from Meta if your monthly active users exceed a certain number), geographic restrictions for certain markets, and prohibitions on using Llama outputs to train models that compete with Meta. For most startups and mid-sized teams, this won’t be a problem. For large-scale consumer products or derivative model training, read the terms carefully.
Running These Models Locally: Quantization Basics
If you want to run any of these models on your own hardware rather than through a hosted API, quantization is the concept you need to understand. Full-precision models store each weight as a 16-bit floating point number. A 7B model in FP16 requires roughly 14GB of GPU memory. Quantization reduces the number of bits per weight — Q4_K_M reduces each weight to approximately 4 bits using importance-weighted allocation, shrinking memory by 50-75% with minimal quality loss on most tasks.
Ollama is the practical starting point for local deployment. It handles quantization automatically, uses GGUF format files, and runs on Mac, Linux, and Windows with a single command. Q4_K_M is the practical standard for most hardware — on a 24GB consumer GPU, it lets you run models in the 13B-30B active-parameter range.
# Install and run Qwen3.6 locally via Ollama
ollama pull qwen3.6:8b
ollama run qwen3.6:8b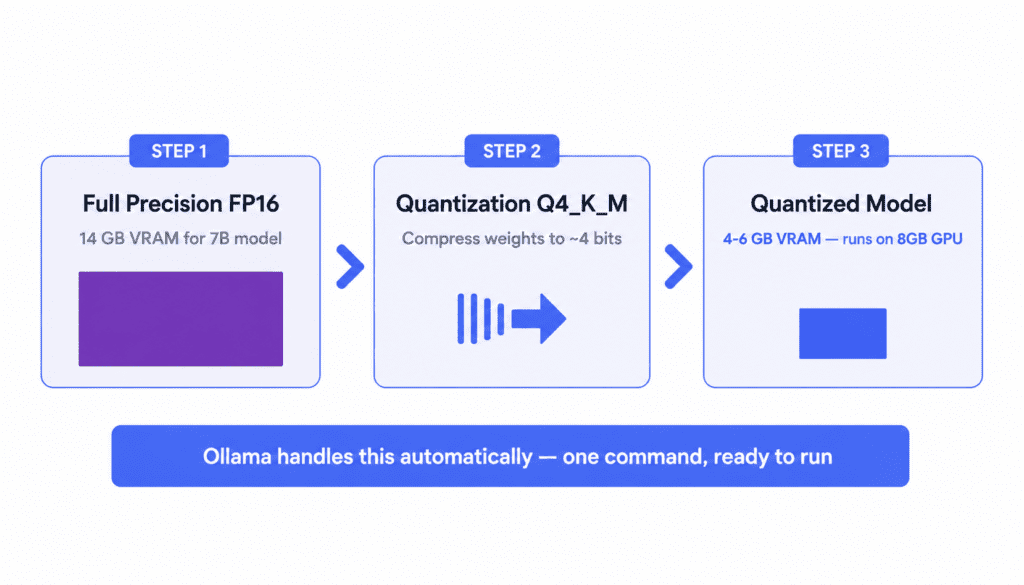
Hardware reality check: running a true frontier model (70B+ active parameters) locally requires either a high-end workstation or a multi-GPU setup. For most developers running experiments, the 7B-14B range with Q4_K_M quantization is the practical sweet spot — fast, manageable memory footprint, and good enough for the majority of development tasks.
How to Actually Choose
This is where I’ll be direct rather than hedge everything with “it depends.”
If you need the clearest commercial licensing and strong multilingual support: Qwen 3.6 (Apache 2.0). It’s the safest legal choice, genuinely strong on benchmarks, and the thinking/non-thinking mode switching is practically useful in production.
If ecosystem, tooling, and community matter most to you: Llama 4 Scout or Maverick. The 10-million-token context window on Scout is unmatched. Just read the license.
If you’re building a production agent in Europe or have GDPR requirements: Mistral Small 4. Apache 2.0, Paris-based company, configurable reasoning depth, self-hostable on reasonable hardware.
If raw reasoning performance is the constraint and you can use a hosted API: DeepSeek V4 Pro. MIT license, strongest neutral agentic benchmark score among open weights.
One thing worth being honest about: the open-source landscape at this tier moves monthly. GLM-5.1, Kimi K2.6, and MiMo-V2.5-Pro emerged within a 30-day window in early 2026 and immediately topped neutral benchmarks. What’s best today may not be best in three months — which is actually an argument for building your stack around permissively licensed models you can swap out cleanly rather than locking into any one family.
For understanding how these models decide what to output — the transformer architecture and next-token prediction that underpins all of them — the how large language models work post covers the mechanics in detail.
FAQ
What is the best open source large language model in 2026?
It depends on the workload. By the neutral Artificial Analysis Intelligence Index composite, Kimi K2.6 leads open-weight models. For agentic coding, DeepSeek V4 Pro leads the GDPval-AA leaderboard. For clearest Apache 2.0 licensing and multilingual support, Qwen 3.6 is the strongest option. Llama 4 leads on context length (10M tokens for Scout) and has the deepest tooling ecosystem. There is no single best answer — the choice is a function of your workload, hardware, and licensing constraints.
Can I run these models on a regular computer?
Smaller quantized variants, yes. Ollama with a Q4_K_M quantized 7B-8B model runs on most modern laptops with 16GB of system RAM, including CPU-only inference. On a 24GB GPU, you can run models in the 14B-30B active-parameter range comfortably. Frontier-class models with 40B+ active parameters need dedicated GPU hardware. Apple Silicon Macs with unified memory (M3 Pro/Max/Ultra) are surprisingly competitive for local inference given their memory bandwidth.
What does open source mean for large language models?
In this space, “open source” most commonly means open-weight — the model weights are publicly available to download. It doesn’t always mean the training code or training data are available. License terms vary significantly: Apache 2.0 and MIT are fully permissive; Llama’s community license has usage and geographic conditions. Always check the specific license before building a production application.
How do I compare large language models objectively?
Use independent composite benchmarks rather than single-task scores. The Artificial Analysis Intelligence Index aggregates 10 independent evaluations. SWE-Bench Verified and Pro measure real software engineering capability. Avoid drawing conclusions from MMLU alone — it’s been trained on too heavily to be a reliable signal in 2026. For your specific use case, running your own evaluation on representative tasks is more useful than any leaderboard.

