How Large Language Models Work: A Genuine Under-the-Hood Explanation
Here’s the myth: large language models are some kind of sophisticated language understanding engine. They “read” text, “comprehend” it, and “decide” what to say.
None of that is what’s happening.
Large language models are, at their core, doing one thing: predicting the next token given everything that came before it. That’s the training objective. That’s the task. And the unsettling, genuinely surprising discovery that the last decade of research produced is that doing this one thing, at sufficient scale, across enough data, produces something that looks a lot like reasoning, translation, coding, and summarization — without those capabilities ever being explicitly trained.
Understanding how that works requires understanding four things: what a token is, how the transformer architecture made large-scale training feasible, what pre-training actually does, and how RLHF turns a capable but unreliable model into something useful. Each of these is a design decision, and each one is worth understanding on its own terms.
Table of Contents
What a Large Language Model Actually Is
Definition: A large language model is a neural network trained on massive text corpora to predict the probability distribution over the next token in a sequence, given all preceding tokens. The “large” refers to the number of parameters — learned numerical weights — which in modern models range from billions to trillions.
The key word in that definition is predict. Not understand. Not reason. Predict. Given the sequence “The capital of France is”, the model outputs a probability distribution over every token in its vocabulary, and “Paris” should have a very high probability. That’s the entire training signal.
What makes this interesting is that producing accurate next-token predictions across enough varied text forces the model to learn — implicitly, through gradient descent — whatever internal representations are necessary to make those predictions. Grammar. World knowledge. Logical relationships. Code syntax. Mathematical patterns. None of these were taught directly. They emerged as necessary tools for doing next-token prediction well.
Tokens Are Not Words
Before getting to the architecture, the token concept is worth spending a moment on because it causes genuine confusion.
A token is a subword unit, not a word. The vocabulary of a large language model contains roughly 50,000 tokens, each representing a frequently occurring sequence of characters. Common short words map to single tokens (“cat”, “the”, “and”). Rare or long words get split into multiple tokens (“unprecedented” might become “un”, “prec”, “edented”). Punctuation, whitespace, and code characters all get their own tokens.
Why subwords rather than words? Words as tokens create a vocabulary that’s too large and can’t handle new words at inference time. Characters as tokens create sequences that are too long and lose meaningful structure. Subword tokenization, developed in the research literature, hits the right balance.
The context window is the maximum number of tokens the model can process in a single forward pass. GPT-3, the 175-billion parameter model described in Brown et al. (2020), had a context window of 2,048 tokens. Modern models have pushed this into the hundreds of thousands. Within this window, every token has full access to every other token — which is only possible because of the transformer architecture.
Why the Transformer Architecture Changed Everything
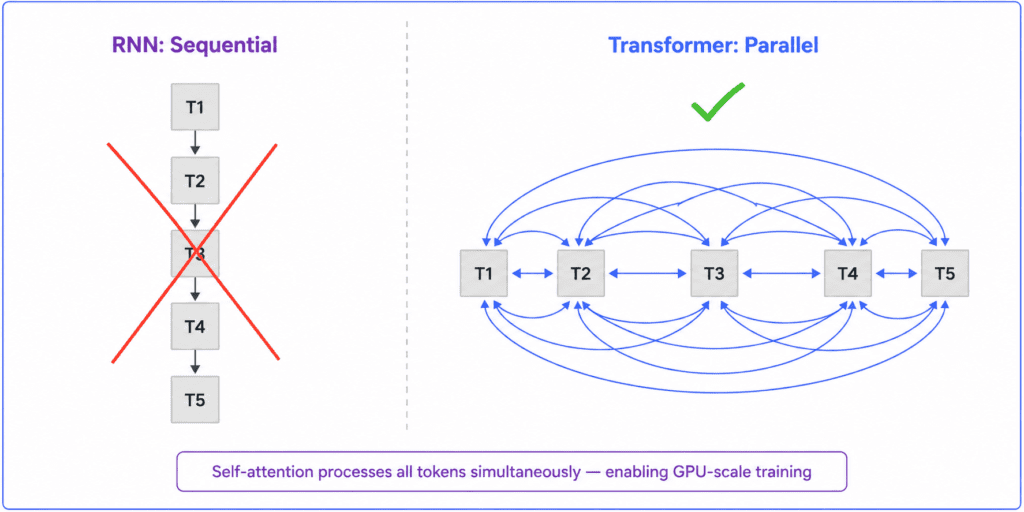
Before transformers, language models used recurrent neural networks (RNNs) and long short-term memory networks (LSTMs). These processed sequences token by token, left to right. Each new token was processed as a function of the previous hidden state plus the new input — which meant you couldn’t process token 100 until you’d processed tokens 1 through 99. Sequential computation was baked in.
This was a fundamental bottleneck. You can’t train on billions of tokens efficiently when processing is sequential. The computation can’t be parallelized across modern GPU hardware.
Vaswani et al. (2017) removed this constraint entirely. The transformer they proposed, described in their paper Attention Is All You Need, replaced recurrence with self-attention — a mechanism where every position in the sequence attends to every other position simultaneously, in parallel.
The self-attention mechanism works like this. Each token is projected into three vectors: a query (what am I looking for?), a key (what do I contain?), and a value (what information do I carry?). Attention scores between any two tokens are computed as the dot product of their query and key vectors, scaled by the square root of the vector dimension to prevent gradients from vanishing in large models, then passed through a softmax to produce attention weights. The output for each token is a weighted sum of value vectors across the whole sequence, weighted by those attention scores.
Mathematically, Vaswani et al. expressed this as:
Attention(Q, K, V) = softmax(QKᵀ / √dk) · VWhere Q, K, V are matrices of queries, keys, and values, and dk is the key dimension.
But the original paper didn’t stop at single-head attention. They proposed multi-head attention: running this attention mechanism eight times in parallel, each with different learned projections into different subspaces of the representation. Each head can specialize in attending to different types of relationships — one head might track syntactic dependencies, another might capture coreference, another might handle positional proximity. The outputs are concatenated and projected back to the model dimension.
One consequence of removing recurrence: the model has no inherent sense of sequence order. Vaswani et al. addressed this with positional encodings — sinusoidal functions of varying frequencies added to the token embeddings before the first layer. This injects position information without requiring recurrence. In modern models, learned positional embeddings or more sophisticated schemes like RoPE (Rotary Position Embedding) are more common, but the underlying problem they solve is the same.
The practical result of all this: transformers are massively parallelizable across GPUs. Training that would have taken weeks on RNN architectures could run in hours. This is what made training on the scale needed for large language models computationally feasible in the first place.
For a deeper breakdown of how the transformer architecture works across different model types, the Transformers Explained post covers the encoder-decoder distinction and how attention patterns differ between them.
Pre-Training: What the Model Is Actually Learning
Pre-training is the phase where the model learns from raw text at scale. Brown et al. (2020) describe GPT-3’s training data in their paper: approximately 300 billion tokens drawn from a filtered subset of Common Crawl (web text), WebText2 (curated web pages), two Books corpora, and English Wikipedia. Common Crawl was filtered aggressively — fuzzy deduplication, quality filtering against high-quality reference corpora, document-level deduplication to prevent test contamination.
During pre-training, the model sees a token sequence and must predict the next token. Cross-entropy loss between the predicted probability distribution and the actual next token provides the gradient signal. Backpropagation adjusts all the weights slightly, so the prediction improves. Do this across 300 billion tokens and 175 billion parameters, and the model’s weights end up encoding an enormous amount of structured knowledge about how language works.
What the model is learning is hard to characterize precisely because it’s not learning any explicitly named capability. It’s learning whatever is necessary to predict text accurately across a wildly varied corpus of human writing. The research literature from Brown et al. frames this as the model developing “a broad set of skills and pattern recognition abilities” during pre-training, which it can then deploy at inference time through in-context learning — performing tasks purely from examples shown in the prompt, without any parameter updates.
The GPT-3 paper demonstrated that at sufficient scale, this in-context learning capability becomes remarkably powerful. GPT-3 could perform translation, arithmetic, question answering, and common-sense reasoning tasks, sometimes matching fine-tuned models that had seen thousands of labeled examples, purely from a few demonstrations in the prompt. No gradient updates. No task-specific training.
The Alignment Problem: Why Pre-Training Isn’t Enough
Here’s what the InstructGPT paper by Ouyang et al. (2022) puts plainly at the outset: “the language modeling objective is misaligned.” Predicting the next token on web text is different from “follow the user’s instructions helpfully and safely.”
A model trained purely on next-token prediction on internet data learns from everything on the internet — including toxic content, misinformation, and text that demonstrates unhelpful behavior. The objective function rewarded accurately predicting that text, not avoiding it. The result is a model that can be helpful, but is also capable of generating harmful, untruthful, or simply useless outputs, because none of those failures are penalized by the pre-training objective.
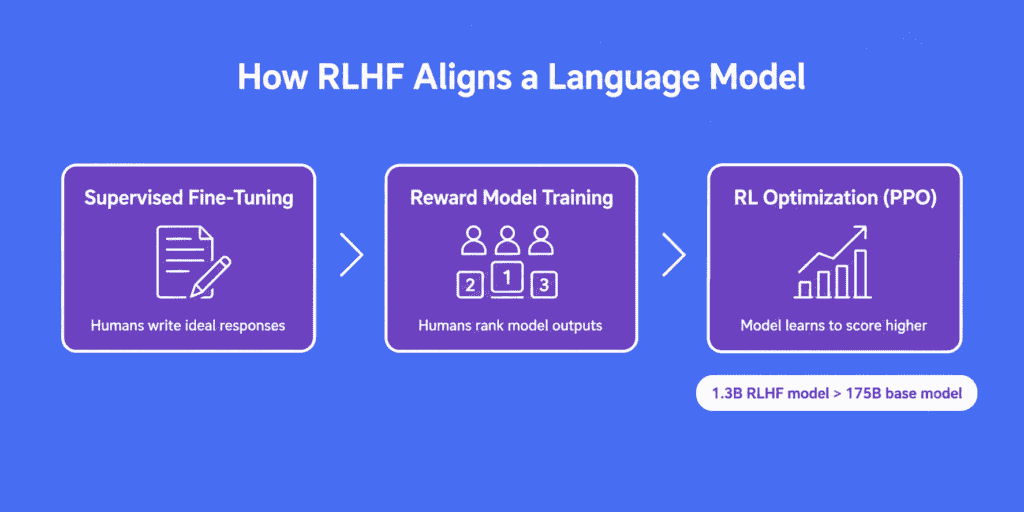
Reinforcement Learning from Human Feedback (RLHF) is how this gets addressed. The Ouyang et al. paper describes the process in three stages.
First, supervised fine-tuning. Human labelers wrote example responses to a set of prompts, demonstrating the desired behavior. The pre-trained model was fine-tuned on these demonstrations via supervised learning. This gave the model a reasonable prior on what “helpful response” looks like.
Second, reward model training. A new dataset was collected where model outputs for the same prompt were ranked by human labelers from best to worst. This ranking data was used to train a separate reward model: a neural network that predicts which output a human would prefer. The reward model learned to score completions in a way that correlates with human preferences.
Third, reinforcement learning optimization. The fine-tuned language model was further trained using Proximal Policy Optimization (PPO), a reinforcement learning algorithm, with the reward model providing the reward signal. The language model generated outputs, the reward model scored them, and the RL algorithm updated the language model’s weights to generate outputs that score higher.
The result, as Ouyang et al. found, was striking. A 1.3-billion parameter InstructGPT model — trained with RLHF — was preferred by human evaluators over the 175-billion parameter base GPT-3 model. A model that’s roughly 100 times smaller by parameter count produced outputs humans rated as better, because it was optimized toward what humans actually want rather than toward raw next-token prediction accuracy.
This is one of the most practically important findings in recent language model research. Raw scale gets you capability. Alignment gets you usefulness.
Emergent Behavior: The Part Nobody Fully Understands
Wei et al. (2022) documented a phenomenon that’s still not completely explained: as language models scale up, certain capabilities appear suddenly and discontinuously.
Their paper defines an emergent ability as “not present in smaller models but present in larger models” — one that “cannot be predicted simply by extrapolating the performance of smaller models.” On a graph of model scale versus task performance, emergent abilities show a specific pattern: near-random performance below a critical scale threshold, then a sharp jump to substantially above-random above it. The paper calls this a phase transition, borrowing language from physics.
Examples they observed included multi-step arithmetic, chain-of-thought reasoning, and various language understanding benchmarks where smaller models showed essentially random performance that jumped sharply at larger scales. These abilities were never explicitly trained — they emerged as a consequence of scale.
There’s a genuine ongoing debate about what’s actually happening. A 2023 paper from Stanford researchers (Schaeffer, Miranda, and Koyejo) argued that many apparent emergent abilities may be artifacts of nonlinear or discontinuous evaluation metrics. When you switch to smoother metrics, the discontinuities disappear and performance improves gradually. Under this view, emergence might be a measurement phenomenon rather than a genuine property of the models.
The debate hasn’t resolved. What both sides agree on is that scaling produces capabilities that weren’t anticipated, and that predicting what a model can do from smaller model performance is harder than simple extrapolation suggests.
What Large Language Models Don’t Do
Two things worth being clear about because they’re commonly misunderstood.
Large language models have no persistent memory across conversations. Each inference call processes only the tokens in the current context window. There is no learning, no memory formation, no information retention between separate calls. Whatever the model appears to “remember” within a conversation is because those prior turns are included in the context window as text.
Large language models don’t do symbolic reasoning in any formal sense. They don’t maintain a logical proof state, don’t manipulate abstract symbols according to formal rules, and don’t guarantee consistency between statements. What looks like reasoning is pattern completion that has learned to follow reasoning-like patterns from training data. On many tasks, this produces correct results. On others, particularly tasks requiring precise formal logic or counting, it fails in ways that expose the underlying probabilistic nature of next-token prediction.
Neither of these is a criticism. They’re constraints that follow directly from the architecture and training objective. Understanding them is what lets you use these models effectively and predict where they’ll fail.
FAQ
What is a large language model in simple terms?
A large language model is a neural network trained to predict the next word (technically, the next token) in a sequence, over billions of examples of text. By doing this at sufficient scale — billions of parameters, hundreds of billions of training tokens — the model learns internal representations of language, world knowledge, and reasoning patterns that let it generate coherent, contextually appropriate text across a wide range of tasks.
What does “training” a large language model actually mean?
Training means repeatedly showing the model text sequences, having it predict what comes next, computing how wrong the predictions were, and adjusting the model’s internal numerical weights to make those predictions slightly more accurate. Repeat this billions of times across a massive text corpus and the weights converge toward values that make useful predictions. Pre-training is this process at scale. Fine-tuning applies the same process on a smaller, more targeted dataset after pre-training is complete.
What is RLHF and why does it matter?
RLHF stands for Reinforcement Learning from Human Feedback. It’s the alignment process that turns a capable pre-trained model into one that’s actually helpful and follows instructions. Human labelers rank model outputs from better to worse, a reward model learns to predict those preferences, and the language model is then optimized using reinforcement learning to generate outputs the reward model scores highly. The Ouyang et al. (2022) paper found that a 1.3B-parameter RLHF-trained model was preferred over the 175B base model — alignment matters more than raw scale for practical usefulness.
What is a context window?
The context window is the maximum number of tokens a model can process in a single forward pass. Everything the model can “see” — the conversation history, the document, the instructions — must fit within this window. Beyond the context window, the model has no access to information. GPT-3 had a 2,048-token window. Modern models have pushed this to hundreds of thousands of tokens, though longer contexts introduce their own performance tradeoffs.
The piece of this that I find worth sitting with: nobody designed language models to reason, to translate, or to write code. Those capabilities emerged from training a neural network to predict the next token across enough text. Vaswani et al.’s self-attention mechanism made training at that scale feasible. Brown et al. demonstrated what scale actually produced. Ouyang et al. showed that alignment determines whether any of that capability is actually useful. And Wei et al. found that emergent abilities appear in ways even researchers couldn’t predict from smaller models.
None of that was obvious in advance. Some of it still isn’t fully understood now.

