LangChain vs LlamaIndex 2026: Which Framework Wins?
Six months into a production knowledge-base project, I admitted to my team that we’d picked the wrong framework.
We were using LangChain for a document-heavy RAG pipeline. Thousands of internal policy documents, contract PDFs, technical specs. The retrieval was mediocre. Chunks were coming back fragmented. Context windows were filling up with adjacent text that had nothing to do with the query. I spent two weeks tuning splitter parameters before someone pointed out that LlamaIndex was solving this problem structurally, at the framework level, with less code. Switching cost us a sprint. The lesson stuck.
This post is what I wish I’d read before that project started.
LangChain and LlamaIndex are the two dominant frameworks for building large language model applications in 2026. Both are open-source, both support every major language model provider, and both have shipped production systems at serious scale. The question isn’t which is better in the abstract. It’s which fits the problem you’re actually solving.
Table of Contents
What Both Frameworks Actually Are
Before the comparison, a quick grounding.
LangChain started as a way to chain language model calls together. It’s grown into a family of focused packages: langchain-core for primitives, langchain-community for integrations, and most importantly, LangGraph for stateful agent orchestration. LangChain is now primarily an orchestration framework. It happens to be excellent at retrieval, but that’s not where it was designed from.
LlamaIndex started as GPT Index. Its entire architecture was built around one problem: getting the right context in front of a language model at the right time, at scale, across heterogeneous document types. Everything in the framework — nodes, indices, query engines, retrievers — exists to serve that core goal.
Both frameworks have pushed into each other’s territory. LlamaIndex now has Workflows for multi-step agent pipelines. LangChain now has retrieval components that handle many standard patterns. But the original DNA still matters, because it shapes the defaults, the abstractions, and the rough edges.
LangChain: Where It Actually Wins
LangChain’s biggest differentiator in 2026 isn’t its chains or its document loaders. It’s LangGraph.
LangGraph models agent behavior as a directed graph where nodes are Python functions and edges represent state transitions. A central State object, typed with TypedDict or Pydantic, persists throughout the entire execution. When the agent calls a tool, the result flows back into state. When it needs to branch based on output, that’s a conditional edge. When it needs to loop and retry, that’s a cycle in the graph.
The feature that most teams underestimate until they need it: built-in checkpointers. LangGraph can save full agent state to SQLite, PostgreSQL, or Redis between steps. That means an agent can pause mid-workflow, waiting for human approval or an external event, persist everything, and resume hours or days later exactly where it stopped. This is the statefulness gap — and it matters a lot for production agents. Implementing equivalent behavior in most other frameworks means building that persistence layer yourself.
LCEL (LangChain Expression Language) handles simpler composable pipelines. Streaming, batching, and async execution are first-class. For applications that need to combine multiple tools, maintain conversation memory across turns, and route dynamically based on what a model returns, LangChain’s abstractions fit cleanly.
The integration breadth is real and valuable. LangChain has over 500 integrations across language model providers, vector stores, document loaders, tools, and output parsers. When a new API ships, a LangChain integration usually exists within weeks. For teams wiring together many third-party services, this ecosystem depth saves time that would otherwise go into custom integration code.
Where LangChain still struggles is debugging. The abstraction layers in complex LCEL chains can be opaque when something goes wrong. Understanding what’s happening inside a misbehaving pipeline requires reading through multiple levels of indirection. LangSmith, the first-party observability tool, helps significantly — it captures full execution traces with token counts and cost per step. But the need for a dedicated observability tool to understand your own framework is itself a signal.
LangChain went through painful API churn in versions 0.1 through 0.3. Import paths changed, constants were renamed, previously used APIs were removed. Teams that adopted early paid for it in broken deployments. The framework reached 1.0 in October 2025 and is stable now. If you’re starting fresh today, this history is mostly irrelevant. If you’re inheriting a project built on pre-1.0 LangChain, budget time for the upgrade.
Best fit: stateful multi-step agents, applications with complex branching logic and tool use, systems that need human-in-the-loop workflows, teams that need broad integration coverage across many third-party services.
LlamaIndex: Where It Actually Wins
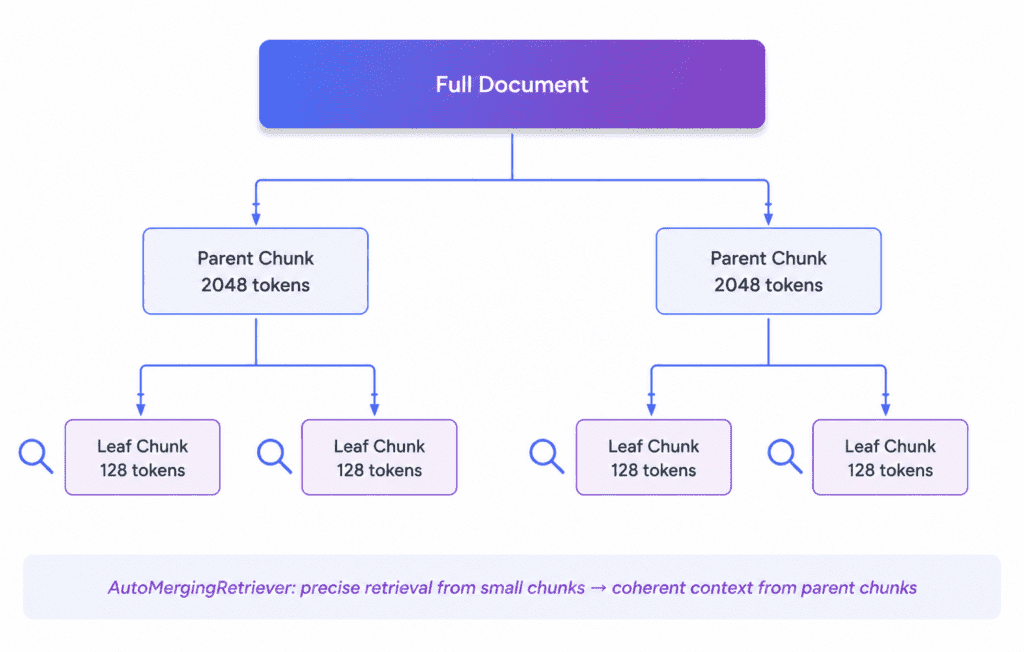
LlamaIndex’s retrieval architecture is genuinely more sophisticated than anything LangChain ships by default, and understanding why requires understanding how it handles chunks.
A basic RAG pipeline splits documents into fixed-size chunks, embeds them, and retrieves the top-k most similar chunks at query time. This approach has a structural problem: the retrieved chunks are often too small to contain enough context, but retrieving larger chunks means pulling in more irrelevant content. LlamaIndex solves this with hierarchical chunking.
The framework parses documents into a coarse-to-fine hierarchy. A document might become chunks of 2048 tokens at the top level, 512 tokens at the middle level, and 128 tokens at the leaf level. Each node carries a reference to its parent. At query time, embedding similarity search runs against the small leaf nodes. Then the AutoMergingRetriever kicks in: if a sufficient number of retrieved leaf nodes all belong to the same parent chunk, the framework swaps them out for the parent node, returning a larger, coherent block of context instead of several disparate fragments. You get precise retrieval accuracy from small chunks and coherent context delivery from large chunks, dynamically, per query.
This is the mechanism I was missing during those two weeks of splitter tuning. It’s not a configuration option in LangChain — it’s a structural retrieval primitive in LlamaIndex.
Sub-question decomposition handles another pattern that basic RAG handles poorly: queries that span multiple documents or require synthesizing information from different sections. LlamaIndex breaks the original query into simpler sub-questions, retrieves relevant chunks for each independently, and merges the results before synthesis. The language model gets pre-organized, query-specific context rather than a single blob of top-k results.
The practical impact shows up in code volume. For an equivalent RAG pipeline, LlamaIndex typically requires 30–40% less code than LangChain because the retrieval abstractions are purpose-built. This is not trivial. Less code means faster iteration when you’re tuning chunking strategies or swapping retrieval methods.
For a deeper look at what RAG actually is and why the retrieval layer matters so much, the RAG explained post covers the fundamentals before you dive into framework choices.
LlamaIndex Workflows — its answer to LangGraph — use an event-driven async model where steps are decorated Python functions and events are Pydantic models. Flexible, async-first, integrates cleanly with FastAPI. The important difference from LangGraph: Workflows are stateless by default. External state management is your responsibility. For request-response agents this doesn’t matter. For multi-turn conversational agents with persistent memory, it means more work.
Best fit: production RAG pipelines over large document corpora, enterprise knowledge bases, document intelligence systems across mixed formats (PDFs, SQL, JSON, spreadsheets), any application where retrieval quality is the primary performance lever.
The Economics Nobody Talks About
LlamaIndex carries approximately 1,600 tokens of framework overhead per request. LangGraph carries approximately 2,400 tokens. The 800-token difference sounds minor.
At 100 concurrent users running 50 queries each per day, that’s 5,000 requests daily. 800 tokens × 5,000 requests = 4 million extra tokens per day from framework overhead alone, at whatever rate your language model provider charges. At GPT-4o pricing, that’s roughly $60 per day in overhead that has nothing to do with your actual prompts or responses. Monthly, that’s $1,800. Over a year, it’s $21,000 from framework selection alone.
At scale, token overhead is a real budget line item. Most comparison articles present it as a footnote.
The Honest Production Answer
Many teams don’t choose between LangChain and LlamaIndex. They use both.
LlamaIndex handles data ingestion, chunking, indexing, and retrieval. LangGraph handles orchestration, tool routing, branching logic, and memory. The two layers compose cleanly because LlamaIndex retrieval components work as retrievers inside LangGraph nodes. You get LlamaIndex’s retrieval depth — hierarchical chunking, auto-merging, sub-question decomposition — wired into LangGraph’s stateful agent graph.
This isn’t a cop-out answer. For sufficiently complex applications where retrieval quality and agent sophistication both matter, the combined stack is genuinely the right architecture. The cost is maintaining familiarity with both frameworks. For teams where the hard part is primarily retrieval, LlamaIndex alone is often enough. For teams where the hard part is orchestration with modest retrieval needs, LangChain alone is usually enough.
Decision Framework
| Your primary challenge | Recommendation |
|---|---|
| Complex multi-step agents with tools and memory | LangChain + LangGraph |
| RAG over large or mixed document corpora | LlamaIndex |
| Human-in-the-loop workflows with persistent state | LangChain + LangGraph |
| Retrieving accurately from heterogeneous enterprise docs | LlamaIndex |
| Integrating many third-party APIs and services | LangChain |
| Fast iteration on retrieval quality | LlamaIndex |
| Both: complex agents + high-quality retrieval | LlamaIndex retrieval + LangGraph orchestration |
One honest note on the table above: if you’re building your first production language model application and you’re not sure which category you fall into, start with LlamaIndex. The retrieval abstractions are more forgiving of early architectural decisions, the upgrade path has been historically more stable, and most applications turn out to be primarily retrieval problems once they’re in production.
FAQ
Is LangChain or LlamaIndex better for beginners?
LlamaIndex has a steeper initial learning curve. The concepts — nodes, indices, query engines, postprocessors — take longer to internalize than LangChain’s chain-and-agent model. But once understood, LlamaIndex’s abstractions tend to produce cleaner production code with fewer surface area surprises. LangChain’s gentler initial ramp can lead to architectures that are harder to debug at scale. Neither is obviously better for beginners; it depends on whether you learn better by building quickly or by understanding the model first.
Can you use LangChain and LlamaIndex together in the same project?
Yes, and many production systems do. LlamaIndex retrieval components are compatible as retrievers inside LangChain and LangGraph pipelines. A common pattern: use LlamaIndex for document ingestion, hierarchical indexing, and query-time retrieval; use LangGraph to orchestrate the agent workflow that decides when to retrieve, how to use tools, and how to synthesize results. The integration points are clean and well-documented on both sides.
What happened to the old “LangChain for agents, LlamaIndex for RAG” rule?
It’s less clean in 2026 than it was in 2023. LlamaIndex now has Workflows for multi-step agent pipelines. LangChain has retrieval components that handle standard RAG patterns. But the original split still captures the dominant strength of each framework. LangGraph’s stateful persistence and explicit graph control are genuinely ahead of LlamaIndex’s Workflows for complex agent use cases. LlamaIndex’s hierarchical retrieval and auto-merging are genuinely ahead of LangChain’s component-based approach for document-heavy systems. The boundaries blurred but the core strengths held.
The mistake I made on that knowledge-base project was treating both frameworks as interchangeable tools for connecting a language model to documents. They’re not. They make different architectural bets, and those bets compound quietly through every abstraction layer you build on top. Pick the framework whose opinions match your problem, not the one with more GitHub stars.

