Deep Learning vs Machine Learning vs AI: What’s Actually the Difference?

Here’s the misconception most people have: they think AI, machine learning, and deep learning describe competing approaches like you pick one or the other. But that’s not how it works. The real difference is hierarchy. They’re nested. AI is the broadest category. Machine learning is a subset of AI. Deep learning is a subset of machine learning. Understanding the difference between them isn’t just academic – it changes how you evaluate tools, build solutions, and understand what’s actually possible.
They’re not. They’re nested. AI is the broadest category. Machine learning is a subset of AI. Deep learning is a subset of machine learning. Every deep learning system is a machine learning system. Every machine learning system is doing AI. The confusion comes from how the media uses all three terms interchangeably, usually defaulting to “AI” when they mean a very specific type of neural network trained on a very large dataset.
Getting this wrong leads to bad conversations and worse decisions. So let’s be precise about it. (Feature engineering, by the way, is the hidden work behind most machine learning projects here’s how to approach it.)
Table of Contents
The Three Circles: How They Actually Nest
Think of three concentric circles. The outermost one is AI. Inside it sits machine learning. Inside that sits deep learning.
Artificial intelligence is the big umbrella. Anything that makes a computer do something that would require intelligence if a human did it counts as AI. That includes rule-based systems written by hand in the 1980s, chess engines that use search trees, expert systems, and yes, modern neural networks. The category is enormous and mostly historical at this point.
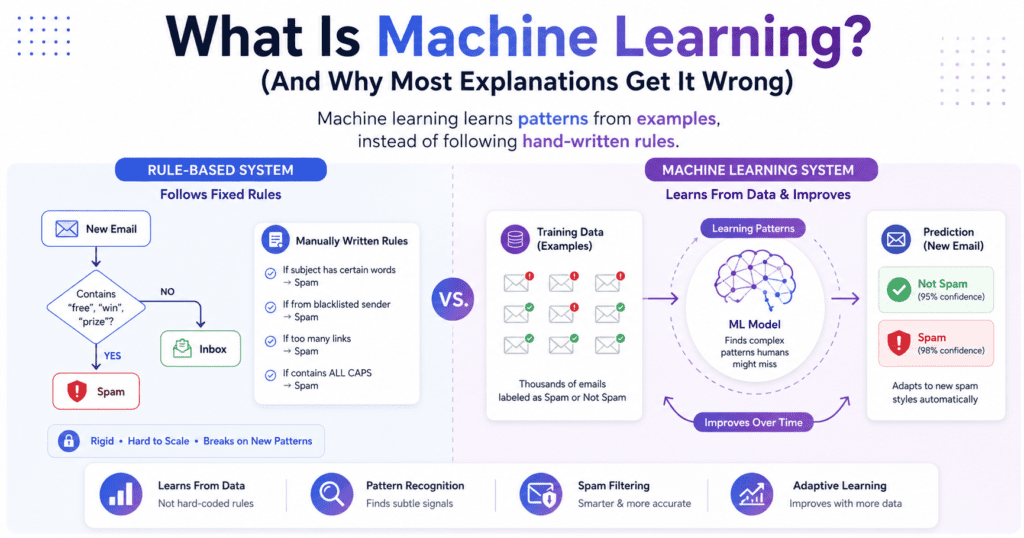
Machine learning is the subset of AI where the system learns from data instead of following hand-written rules. You give it examples, it finds patterns, it makes predictions. You don’t program the rules yourself. That’s the defining difference between machine learning and traditional rule-based AI.
Deep learning is the subset of machine learning that uses neural networks with many layers, what researchers call deep architectures. It’s one type of machine learning model, not a different thing from machine learning entirely. A random forest is machine learning. Linear regression is machine learning. A transformer running a large language model is also machine learning, specifically deep learning. Same category, different model architecture.
So when someone says “we’re using AI,” they’ve told you almost nothing. When they say “we’re using machine learning,” you know the system learns from data. When they say “we’re using deep learning,” you know it involves multi-layer neural networks.
What AI Actually Means (Stripped of the Hype)
The term “artificial intelligence” has been around since 1956, and it’s meant something different in almost every decade since. In 2026, when people say AI in a product context, they almost always mean one of two things: a machine learning model, or a large language model specifically.
The older meaning of AI, systems that encode human expert knowledge as explicit rules, has largely fallen out of fashion. Rule-based systems still exist and still run in production in industries like banking and insurance. They work well when the rules are known and stable. They fail when the problem space is messy, the rules are unclear, or the exceptions outnumber the rules.
That’s where machine learning came in. Instead of writing rules, you show the system thousands of examples and let it infer the rules on its own. For problems where you have data and the patterns are too complex to hand-code, machine learning beats rule-based systems. This shift, from writing rules to learning from data, is the most important conceptual divide in the whole space.
What hasn’t changed: the term AI still gets applied loosely to anything that seems impressive. If a company calls their product “AI-powered” and it’s actually a decision tree, that’s technically defensible but practically misleading. You’re not wrong to push back and ask what kind of model is actually running.
Traditional Machine Learning: Feature Engineering Is the Job
When most practitioners say traditional machine learning, they mean the class of algorithms that sit above deep learning in terms of interpretability and below deep learning in terms of raw performance on perception tasks. Random forests, gradient boosting, logistic regression, SVMs, k-means. These are traditional machine learning.
The defining characteristic: traditional machine learning requires humans to do feature extraction before the model sees the data. You can’t just hand a traditional machine learning model raw pixels and expect it to classify images. You need to transform those pixels into structured numerical features first, edge counts, color histograms, texture gradients, or whatever the domain suggests. That process of deciding what to measure and how to represent it is feature engineering, and with traditional machine learning, it’s most of the work. This is why feature engineering remains one of the highest-ROI skills in applied ML work.
This isn’t necessarily bad. Feature engineering is a place to inject domain expertise, and sometimes domain expertise beats scale. In 2026 on tabular data, a well-tuned XGBoost model with good features still competes with or beats deep learning approaches in most practical settings. The benchmarks that show deep learning winning at everything are almost always benchmarks on images, text, or audio, not on the structured tabular data that most business problems actually look like.
Traditional machine learning also tends to win on interpretability. You can explain why a gradient boosting model made a decision in terms the business understands. Explaining why a deep network made a decision is genuinely hard.
Deep Learning: When the Model Learns Its Own Features
The thing that separates deep learning from everything else is representation learning: the model learns its own internal features rather than relying on human-engineered ones.
You hand a convolutional neural network raw pixels. The first few layers learn to detect edges. The middle layers combine edges into shapes. The later layers combine shapes into objects. You didn’t tell it to look for edges. It figured out that edges are useful because that’s what the training signal pushed it toward. That automatic feature discovery at scale is what makes deep learning so powerful for computer vision, NLP, and audio tasks.
The tradeoff is real, though. Deep learning needs far more data. A traditional machine learning model can learn something useful from a few thousand examples. A deep learning model often needs hundreds of thousands or millions of examples to start performing well on comparable tasks. And training a deep model takes compute resources that a gradient boosting run doesn’t.
The other tradeoff is the model architecture decision. With traditional machine learning, the algorithm choices are relatively limited and well-understood. With deep learning, you’re choosing between CNNs, RNNs, transformers, diffusion models, and a dozen variants of each. The neural networks post covers how these architectures actually work. Getting that architecture decision wrong wastes a lot of time. I’d point you to the neural networks post for a proper walkthrough of how these architectures work, because that deserves its own treatment.
The Honest Comparison: When to Use What
Here’s where I’ll give you an actual opinion rather than a balanced “it depends.”
Use traditional machine learning when: your data is tabular, you have fewer than a few hundred thousand examples, you need to explain your model’s decisions to a non-technical audience, or you’re under time pressure. Tabular data plus XGBoost is still the highest-ROI combination in applied machine learning. The teams reaching for neural networks before exhausting traditional approaches are usually doing it for the wrong reasons. For structured ML tasks, traditional machine learning approaches still outperform neural networks in most business contexts.
Use deep learning when: your input is unstructured (images, text, audio, video), you have large amounts of data and compute, you can tolerate a black box, or you need the kind of complex pattern recognition that traditional machine learning genuinely can’t do. If you’re doing anything in NLP or computer vision seriously, you’re using deep learning.. There’s no realistic alternative at this point.
Use neither for now when: the problem is actually solvable with rules or simple statistics. I’ve seen teams build machine learning pipelines to predict things that a three-line SQL query already handled correctly. The discipline to not reach for machine learning when it isn’t needed is underrated.
See XGBoost documentation and this comparative study on tree-based vs neural networks for tabular data.
The Framing That’s Actually Wrong
The framing I want to push back on: “AI vs machine learning” as a comparison. You’ll see this in articles, in job descriptions, in vendor decks. It implies they’re alternatives.
They aren’t. Asking whether to use “AI or machine learning” is like asking whether to drive a car or a sedan. Machine learning is a type of AI. Choosing machine learning is choosing AI. The question worth asking is which type of machine learning is appropriate for your problem, and whether machine learning is necessary at all.
The reason the wrong framing persists is marketing. “AI” sounds more impressive than “logistic regression.” So products call themselves AI products when they’re running traditional machine learning, or sometimes just statistics. This bothers me more than it probably should, but I think the vagueness has real costs: teams buy “AI” solutions without understanding what they’re actually getting, and then wonder why the system doesn’t work the way the pitch deck implied.
Go Deeper: Related Resources
I kept this at the conceptual level on purpose. If you want to go deeper:
Neural Networks Explained — Deep dive into model architectures (CNNs, RNNs, transformers) that power deep learning
What is Machine Learning? — Foundational post on how learning from data actually works
Feature Engineering Guide — The hidden work that determines whether traditional ML succeeds or fails
Supervised vs Unsupervised Learning — Different ways to structure learning problems
Each builds on concepts introduced here.
I also didn’t cover the philosophical debate about what “intelligence” means, whether current systems “really” understand anything, and where AGI fits. That’s a different conversation with a different kind of answer.
FAQ
Is deep learning better than machine learning?
Not categorically. Deep learning outperforms traditional machine learning on unstructured data like images, text, and audio, especially at scale. On tabular data, traditional machine learning methods like gradient boosting are often competitive or superior with far less compute and data. “Better” depends entirely on the problem, the data you have, and the resources available.
Can you do machine learning without deep learning?
Yes, and often you should. Most applied machine learning problems in business involve structured, tabular data where algorithms like XGBoost, random forests, or logistic regression work well. Deep learning is one approach within machine learning, not a prerequisite or replacement for it.
What’s the difference between AI and a machine learning model?
AI is a broad category covering any system that exhibits intelligent behavior, including rule-based expert systems, search algorithms, and machine learning models. A machine learning model is a specific type of AI that learns patterns from data. All machine learning models are AI, but not all AI systems use machine learning.
The cleaner way to think about this: every time you hear “AI” in a product context, ask what type of model is actually running. That question cuts through most of the marketing fog fast. If they can’t answer it, that tells you something too.
The field will keep producing new architecture types and new names for things. But the nested relationship, AI contains machine learning contains deep learning, isn’t going to change. Build your mental model around that and the terminology churn stops being confusing.