Overfitting in Machine Learning: Why Your Model Is Lying to You

The first time a model of mine seriously overfit, I didn’t notice for two days.
I’d built a classifier for customer churn. Training accuracy was 96%. I was proud. I tuned a few things, got it to 97%, was even prouder. Then I ran it on the holdout set and got 61%. That’s barely better than guessing. The model had essentially memorized the training data and learned nothing that would help it on a new customer it had never seen. And I had spent two days polishing a lie.
Overfitting in machine learning is, in my experience, the single thing that wastes the most hours for people learning ML in 2026. Not because it’s hard to understand, but because it’s sneaky. Your metrics look great. The model seems to work. And then it completely falls apart the moment real data shows up.
Here’s what’s actually happening, and how to stop it.
Table of Contents
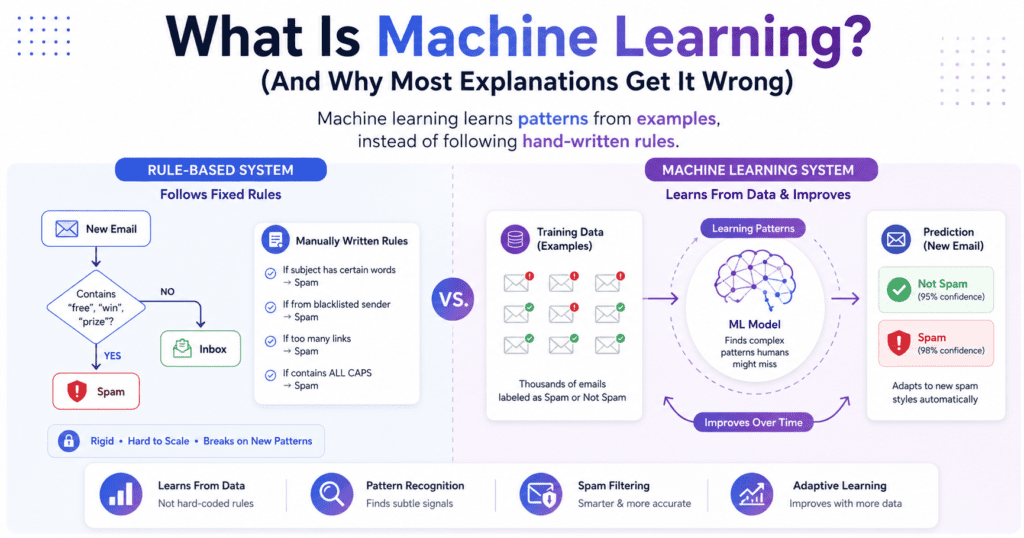
What Overfitting Actually Means
Overfitting happens when a model learns the training data so thoroughly that it starts memorizing noise instead of learning patterns. It nails the examples it’s seen. It fails on anything new.
Definition: Overfitting occurs when a machine learning model learns the training data too closely, capturing noise and random variation alongside genuine patterns. The result is high training accuracy paired with low test accuracy. The model generalizes poorly to new, unseen data.
The analogy I keep coming back to: imagine you’re studying for an exam by memorizing the exact practice test answers. You’ll ace any question that appeared on the practice test. Ask you a slightly different version of the same question and you’re lost, because you memorized answers rather than understanding the underlying concept.
That’s what your model is doing when it overfits. It memorized your training examples, including the weird outliers, the mislabeled rows, the statistical quirks that only exist in that particular dataset. None of that knowledge transfers.
And the really painful part is that your training accuracy genuinely reflects real learning, at least partially. The model did learn something. It just also learned a bunch of garbage on top, and you can’t see the garbage until you test it on data it hasn’t seen.
The Gap That Gives It Away
There’s one number you need to watch: the gap between training accuracy and test accuracy.
A well-fitted model has both numbers close together and both numbers reasonably high. An overfit model has training accuracy that’s suspiciously high while test accuracy falls off a cliff. That gap is the signal.
In code, you’d check it like this:
from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_scoreX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)clf = RandomForestClassifier(n_estimators=100) clf.fit(X_train, y_train)train_acc = accuracy_score(y_train, clf.predict(X_train)) test_acc = accuracy_score(y_test, clf.predict(X_test))print(f”Train: {train_acc:.3f}”) print(f”Test: {test_acc:.3f}”) # if train >> test, you have a problem
If train accuracy is 0.97 and test accuracy is 0.71, that 26-point gap is telling you something. The model didn’t learn the task. It learned your training set.
Some overfitting is normal, by the way. A 2-3 point gap is nothing to panic about. It’s when the gap is wide, or grows wider as you add model complexity, that you need to act. Watching how that gap changes as you train is part of what cross-validation formalizes. I cover that in detail in the cross-validation post, but the short version is: don’t evaluate your model on data you trained on. Ever.
The other diagnostic tool is a learning curve. Plot training accuracy and validation set accuracy against the number of training examples. An overfit model shows training accuracy staying high and flat while validation accuracy stays stuck low. As you add more data, the two curves should converge. If they don’t converge, you have a problem that more data alone might not fix.
Underfitting: The Other Side You Also Need to Worry About
Before getting to fixes, underfitting deserves a paragraph because people tend to forget about it the moment overfitting shows up.
Underfitting is when your model is too simple to learn the actual patterns in the data. Training accuracy is low. Test accuracy is also low. The bias-variance picture here is high bias, low variance. The model is consistently wrong in predictable ways, because it doesn’t have enough complexity to capture the real relationships in the data.
Why does this matter when we’re talking about overfitting? Because most fixes for overfitting push the model toward underfitting if you’re not careful. You add regularization to punish complexity, and if you add too much, you end up with a model that’s now too simple and fails on both sets. You’re trying to thread a needle between the two failure modes, and the technical term for that threading is the bias-variance tradeoff.
The practical consequence: fix overfitting incrementally. Don’t add maximum regularization, retrain, and call it done. Check that you haven’t swung into underfitting territory.
How to Fix Overfitting (and What Actually Works)
There’s no single fix. There are four categories of fixes, and which one works depends on your specific problem.
Get more training data. This is the most reliable fix, and the most annoying one to hear because data collection is expensive. But it works because the more diverse examples your model sees, the harder it is for it to memorize all of them and the more it’s forced to learn real patterns. If you can get more data, do it before trying anything else.
When you can’t get more data, data augmentation is sometimes an option. For images, you flip, rotate, crop, and adjust brightness on existing examples to artificially expand the training set. For tabular data, this is trickier and usually not worth the effort.
Simplify the model. A decision tree with depth 30 can memorize almost anything. A decision tree with depth 4 is forced to find the patterns that actually generalize. Reducing model complexity is often the fastest lever.
For neural networks, this means fewer layers, fewer neurons, or both. For tree-based models, it means lower max depth, higher min samples per leaf. For polynomial regression, it means lower degree. The principle is the same everywhere: a simpler model has fewer opportunities to memorize noise.
Regularization. Regularization adds a penalty to the loss function that discourages large coefficient values or complex structures. L1 regularization (Lasso) pushes some weights to zero entirely, which effectively removes features. L2 regularization (Ridge) pushes weights toward zero without fully eliminating them. For neural networks, dropout randomly deactivates neurons during training, which forces the network to learn redundant representations rather than relying on any single path through the network.
The fiddly part of regularization is tuning the strength. Too weak and it does nothing. Too strong and you underfit.
Early stopping. This one’s specific to neural networks and gradient boosting. As you train more epochs, training loss keeps dropping, but at some point validation loss starts climbing back up. That’s the overfitting inflection point. Early stopping monitors validation loss and stops training the moment it starts consistently going the wrong direction. It’s somewhat janky to implement correctly but works well once you nail the patience parameter.
The Fix Everyone Reaches For First Is Usually Wrong
Here’s the thing nobody tells you: most people’s first instinct when they see overfitting is to reach for regularization, specifically dropout or L2. And it’s often the wrong move.
Before you touch regularization, check your data. A lot of what looks like overfitting is actually a data problem. Small dataset means the model has to memorize because there aren’t enough examples to generalize from. Duplicated rows means the model’s “training” on the same examples multiple times, which inflates training accuracy. Target leakage, where a feature that contains or correlates with the label at prediction time but wouldn’t exist in production, makes training look easy while test performance collapses.
I’ve seen people spend three days tuning regularization parameters on a model that was leaking the target. The regularization did nothing because the problem wasn’t model complexity. It was a data pipeline issue.
Actually, let me rephrase that. Regularization helps when your model is genuinely too complex for the data you have. It doesn’t help when your data is the problem. Diagnosing which situation you’re in before reaching for the toolkit saves a lot of time.
So the order I’d suggest: check your data first, consider a simpler model second, add regularization third. Most tutorials get this backwards, which is why people spend so much time tuning hyperparameters on fundamentally broken pipelines.
What This Post Didn’t Cover
I didn’t go deep on the math behind regularization, specifically the penalty terms in the loss function and how they connect to Bayesian priors. It’s interesting, but it doesn’t change how you use regularization in practice and would’ve doubled the length of this post for marginal gain.
I also didn’t cover ensemble methods as an overfitting mitigation. Random forests and gradient boosting both implicitly reduce overfitting through averaging. That’s a bigger topic that belongs in the individual algorithm posts.
FAQ
What’s the difference between overfitting and underfitting in machine learning?
Overfitting is when a model performs well on training data but poorly on new data, because it’s memorized the training set instead of learning general patterns. Underfitting is when a model performs poorly on both, because it’s too simple to capture real patterns. Both mean poor generalization. The goal is a model that sits between them.
How do I know if my machine learning model is overfitting?
Compare training accuracy to test accuracy. A large gap where training is significantly higher than test is the clearest signal. You can also plot a learning curve: if training accuracy is high and flat while validation accuracy is low and stuck, the model is overfitting. Adding more training data should bring the two curves closer together if overfitting is the real issue.
Does more training data always fix overfitting?
It often helps but not always. If the model is genuinely too complex for the task, more data helps because it’s harder to memorize a large dataset. But if the problem is target leakage, duplicated rows, or data quality issues, more data won’t fix anything. And if you genuinely can’t get more data, model simplification or regularization are the better levers to pull.
The reason I find overfitting worth writing about carefully is that the standard advice gets the order of operations wrong. Fix your data. Simplify your model. Then and only then reach for regularization. You’ll save yourself a lot of hairy debugging sessions on problems that weren’t model complexity problems in the first place.
One thing I still don’t have a fully satisfying answer for: why do larger language models seem to generalize remarkably well despite being absurdly overparameterized? The classical bias-variance picture predicts catastrophe. What’s actually happening is something else, and the theoretical understanding is still catching up. Worth keeping an eye on as the research develops.