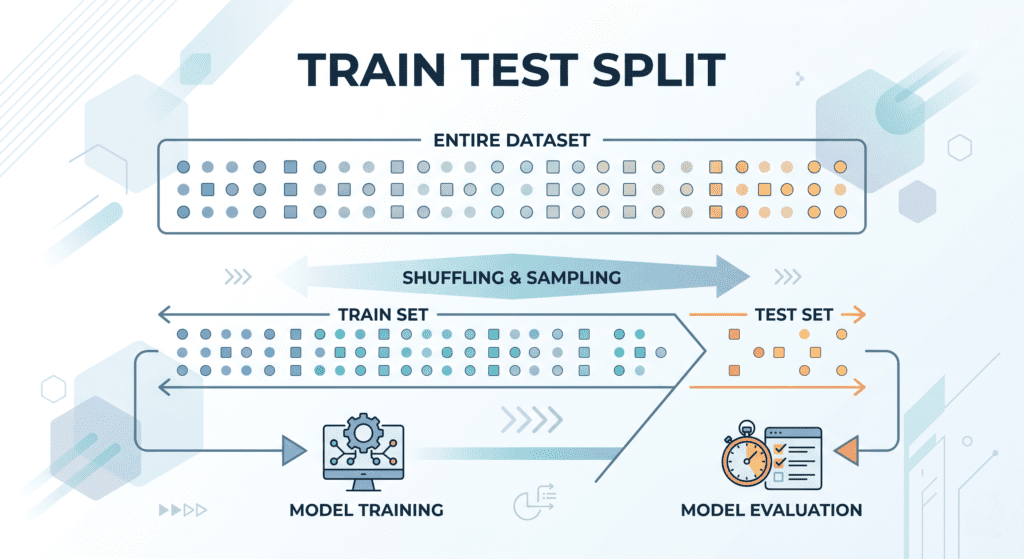
Train Test Split: What Each Set Actually Does (And Where It Goes Wrong)
You’ve got a dataset. You run train_test_split, fit your model, check the accuracy, and it looks solid. You ship it, and performance in production is noticeably worse than your numbers suggested. Nobody changed the code. The model is identical. But the numbers lied.
This happens more often than anyone admits, and in almost every case the cause isn’t the algorithm. It’s the split.
Getting train, validation, and test sets right is one of those fundamentals that tutorials explain quickly and practitioners get wrong slowly. You don’t notice the mistake immediately. Your code runs cleanly, your metrics look reasonable, and the problem only surfaces when real data shows up and the model underperforms in ways that are hard to trace back.
Here’s what each set actually does, why the split matters more than most people treat it, and the specific mistakes that corrupt your evaluation in 2026 without making any noise.
Table of Contents
What the Three Sets Are and Why You Need All Three
Most people understand the two-way split. You train on one chunk, test on another. That’s the foundation. The problem is that a two-way split breaks down the moment you start making decisions based on your test results, and making decisions based on results is the entire point of model development.
Here’s the thing nobody tells you: every time you look at your test set results and adjust your model, you’ve contaminated that test set. Not technically, not in the data. But in practice, your model is now indirectly shaped by the test set. You’ve used it as a guide, which means it’s no longer a clean measure of how your model performs on data it’s never seen.
That’s the exact problem the three-way split solves.
Training set is where the model learns. It sees this data repeatedly, adjusts its parameters on it, and you should expect it to perform well on it. Good training performance means nothing by itself.
Validation set is where you make decisions. Which hyperparameters? Which features? When to stop training? You’re allowed to look at validation results as many times as you want and adjust accordingly. The model never trains on this data, but you’re actively using it to guide development.
Holdout test set is the final verdict. You look at it once, at the very end, after all model decisions have been made. Its only job is to answer one question: how will this model perform on data it’s never seen? If you use it more than once, it stops being a valid answer to that question.
A clean three-way split with roughly 70/15/15 or 80/10/10 proportions covers most cases. For smaller datasets, cross-validation handles the validation piece more reliably, but you still want a separate held-out test set for the final evaluation.
The Four Mistakes That Silently Break Your Evaluation
This is what most articles skip: not the theory, but the specific ways the split goes wrong in practice. These don’t cause errors. They produce results that look valid and aren’t.
Preprocessing before splitting. This is the most common one and it’s rough to diagnose after the fact. If you scale features, impute missing values, or encode categories on the full dataset before splitting, you’ve let the test set contaminate the training process. Your scaler’s mean and standard deviation were computed using test data. Your imputer filled values using statistics that included future rows. The model now has indirect knowledge of the test set baked into its inputs.
The fix is mechanical: split first, preprocess after. Fit your scaler on training data only, then transform the validation and test sets using those same training statistics.
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train) # fit only on train
X_test_scaled = scaler.transform(X_test) # apply the same fit to test — don't re-fitRandom splitting time-series data. If your data has a time dimension, a random split is producing evaluation bias you can’t see. A random 20% holdout from a year of customer data will include rows from December in the training set and rows from March in the test set. Your model will train on future data and test on past data. That’s not a model evaluation. It’s cheating.
For any data with temporal structure, you need a temporal split. Train on the past, validate and test on the future, in that order. The split point is a date, not a random index.
df = df.sort_values('date').reset_index(drop=True)
n = len(df)
train = df.iloc[:int(0.7 * n)]
val = df.iloc[int(0.7 * n):int(0.85 * n)]
test = df.iloc[int(0.85 * n):]This is more of a problem than people expect. Distribution shift between time periods is real, and a model trained on last year’s data should be expected to perform slightly worse on next year’s data. A random split hides that degradation. A temporal split surfaces it.
Using the test set more than once. You run your model, get 87% on the test set, tune a few things, run again, get 89%, and report that. You’ve now tested two different models on the same held-out data and selected the better one. The 89% is no longer an honest measure of performance on unseen data. It’s the better result from two chances at the same target.
The fix: use the validation set to compare and select. Touch the test set only once, after selection is final.
Ignoring class distribution in the split. A random split on an imbalanced dataset will sometimes give you a test set with almost no minority class examples, or a training set with a different class ratio than the full data. Neither produces a reliable model or reliable evaluation. Stratification preserves the original class distribution across all splits.
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y # keeps class ratios intact
)Scikit-learn’s train_test_split documentation covers the stratify parameter in detail, including how it handles multiclass cases.
What “Data Leakage” Actually Means
Data leakage is a broader term and it’s worth being specific about it, because the word gets used for several different things.
At its core, leakage means information from outside the training process has influenced either the training or the evaluation in a way that makes the model look better than it actually is. The split mistakes above are all forms of leakage. But leakage also happens at the feature level.
Target leakage is when a feature in your training data contains information about the label that wouldn’t be available at prediction time. The classic example: predicting whether a patient will be hospitalized, using a feature that records their hospitalization date. If they were hospitalized, the feature exists. If they weren’t, it doesn’t. Your model will find this signal immediately, get near-perfect training accuracy, and be completely useless in practice because the feature doesn’t exist when you need to make the prediction.
The harder cases are features that are correlated with future outcomes through a mechanism that wouldn’t exist in deployment. A feature calculated from a rolling window that inadvertently includes the prediction date. An aggregated metric that was computed on the full dataset before splitting. These are fiddly to catch and require thinking carefully about what data would actually be available at the moment a prediction is made.
I had a particularly embarrassing version of this early on. I was working on a fraud detection model and included a feature that was essentially “was this account flagged in our system.” Turned out that flag was often applied retroactively after fraud was confirmed. The model was effectively using the fraud outcome as a feature. Training accuracy was extraordinary. Real-world performance was not. Two weeks of work, wasted.
When a Simple Two-Way Split Is Fine
I don’t want to make this sound more complicated than it needs to be for straightforward cases.
If you’re not tuning hyperparameters, a two-way train/test split is often enough. Simple linear models with fixed regularization, quick baseline models, exploratory work where you just want a rough sense of generalization: all fine with two sets. The three-way split exists specifically because hyperparameter tuning creates the contamination problem described earlier. No tuning decisions, no contamination problem.
For small datasets where even a 15% validation slice would be too small to be meaningful, cross-validation on the training set handles the validation role more reliably. You still want a held-out test set for the final number, but cross-validation replaces the fixed validation split during development. That’s a longer topic covered in the cross-validation and overfitting post, but the short version is: k-fold cross-validation gives you multiple validation estimates from the same training data, which is more reliable than a single small validation slice.
How Split Ratio Choices Actually Work
The 80/20 split appears everywhere because it’s a reasonable default for medium-to-large datasets. But the right ratio depends on your dataset size, not on convention.
With a million rows, a 1% test set is 10,000 examples, which is more than enough for a stable performance estimate. Keeping 80% of a million rows for training is worth it. With 1,000 rows, a 20% test set is only 200 examples, and performance estimates on 200 examples have high variance. You might want a larger test set for more stable evaluation, or switch to cross-validation entirely.
The principle: you need enough data in training to learn, and enough data in test to evaluate stably. Neither of those numbers is a fixed percentage. Stratification helps both problems by ensuring class balance, which lets smaller splits be more representative.
What This Post Didn’t Cover
Group splits, where multiple rows belong to the same entity (multiple records from the same user, patient, or device), need to ensure the whole group stays in one split. Random splitting of grouped data causes the same person to appear in both training and test, which inflates performance in ways that don’t survive deployment. Scikit-learn’s GroupShuffleSplit handles this.
I also skipped nested cross-validation, which is the right approach when you want unbiased evaluation alongside hyperparameter tuning and have a small dataset. It’s more complex and rarely necessary unless you’re doing careful research evaluation.
FAQ
What is the difference between a validation set and a test set?
The validation set is used during model development to tune hyperparameters and compare models. You can look at it as many times as needed. The test set is a held-out set used only once at the end to measure final model performance. Using the test set to make any development decision contaminates it and makes the final performance estimate unreliable.
What is a good train test split ratio for machine learning?
80/20 is a reasonable default for datasets with thousands of rows or more. For smaller datasets, a larger test percentage gives more stable evaluation, or use cross-validation instead of a fixed validation split. For three-way splits, 70/15/15 and 80/10/10 are both common. The right split depends on dataset size, not convention.
What is data leakage in a train test split?
Data leakage means information from outside the training set has influenced either training or evaluation. The most common form is preprocessing the full dataset before splitting, which lets test set statistics contaminate the training process. Target leakage happens when a training feature contains information about the label that wouldn’t be available at prediction time. Both produce inflated metrics that don’t reflect real-world performance.
The split is one of those decisions that feels mechanical and turns out to matter a lot. Get the order right: split first, then preprocess. Keep the test set locked until you’re done making decisions. For time-ordered data, sort by time and split chronologically. Everything else follows from those three rules.