Cross-Validation in Machine Learning: Why the Way You’re Testing Your Model Is Probably Wrong
Most tutorials teach cross-validation as the solution to bad model evaluation. Run k-fold, average the scores, ship the model. Done right, apparently.
But here’s what they don’t tell you: a huge number of cross-validation setups have a data leakage problem sitting quietly inside them. The scores look honest. The model looks solid. And then it underperforms in production, and you spend a week trying to figure out why.
Cross-validation is the right tool. But there’s a specific way it breaks that almost nobody explains clearly, and if you’ve never had it explained, you’re probably making the mistake right now.
Table of Contents
What Cross-Validation Actually Does
The core problem it’s solving is simple: if you train your model on some data and then test it on that same data, your evaluation is worthless. The model already saw the answers. Its score on training data tells you almost nothing about how it’ll behave on new data it hasn’t encountered.
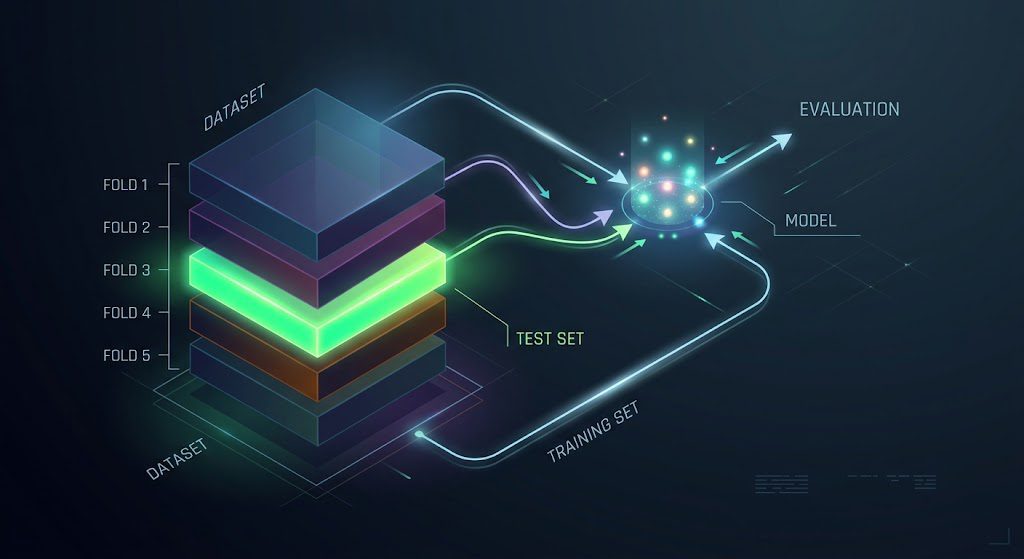
Definition: Cross-validation is a model evaluation technique that estimates how well a model generalizes to independent data by splitting the available dataset into multiple subsets, training on some and testing on others, then averaging results across splits. It gives a more reliable performance estimate than a single train-test split.
The naive solution is a single holdout set: reserve 20% of your data before training, evaluate on it at the end. That works, but it’s noisy. If you got lucky or unlucky with which 20% ended up in the test set, your estimate is off. A small dataset makes this worse.
Cross-validation solves that by repeating the train-and-test process multiple times across different slices of the data, then averaging the results. The variance in your performance estimate drops considerably. You’re no longer trusting a single lucky or unlucky split.
K-Fold: The Method Everyone Learns First
K-fold cross-validation splits your data into k equal groups (folds). The model trains k separate times, each time using k-1 folds for training and the remaining fold as the test set. After all k runs, you average the scores.
With k=5, that means five rounds of training and evaluation, each with a different 20% held out for testing. Every data point gets used for testing exactly once.
from sklearn.model_selection import cross_val_score, KFold
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=100, random_state=42)
kf = KFold(n_splits=5, shuffle=True, random_state=42)
scores = cross_val_score(clf, X, y, cv=kf, scoring='accuracy')
print(f"CV scores: {scores.round(3)}")
print(f"Mean: {scores.mean():.3f}")
print(f"Std: {scores.std():.3f}")
# the std tells you how stable your model is across different slicesThe standard recommendation is k=5 or k=10 for most problems. Five folds is fast. Ten folds gives a lower-variance estimate but costs roughly twice the compute. For most datasets under a million rows, the difference in the final estimate is small.
One thing worth pausing on: shuffle=True matters more than most tutorials mention. Without it, k-fold splits your data in sequential order. If your rows have any natural ordering (by time, by user ID, by collection date), that means some folds will have training data from entirely different conditions than their test fold. Always shuffle unless you’re working with time series, and if you are working with time series, you need a completely different approach anyway (covered later).
The Leakage Problem That Lives Inside Most CV Setups
This is the part nobody explains clearly enough.
When you scale your features, impute missing values, or do any other preprocessing step, you have two options: do it before cross-validation, or do it inside the cross-validation loop.
Most people do it before. It’s simpler to write. You fit a StandardScaler on the full dataset, transform everything, then run cross-validation. Clean code, easy to read, and it introduces data leakage.
Here’s why. When you fit the scaler on the full dataset, the scaling parameters (mean and standard deviation for each feature) are computed using the validation fold data too. Your model never directly sees the raw validation data, but the preprocessing was already influenced by it. The model learns from training data that was scaled using statistics contaminated by the holdout. That’s not a clean evaluation.
# WRONG — preprocessing outside the CV loop
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X) # uses all data including future test folds
scores = cross_val_score(clf, X_scaled, y, cv=5)
# these scores are subtly optimistic# RIGHT — preprocessing inside the CV loop via Pipeline
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
pipeline = Pipeline([
('scaler', StandardScaler()), # fitted fresh on each training fold
('clf', RandomForestClassifier(n_estimators=100))
])
scores = cross_val_score(pipeline, X, y, cv=5)
# now the scaler only sees training fold data, as it would in productionThe Pipeline object is the fix. When you wrap your preprocessing and model into a pipeline and pass that to cross_val_score, scikit-learn handles the fitting correctly inside each fold. The scaler sees only the training portion of each split, exactly the way it would in a real deployment scenario.
For more on what happens when your model looks good in evaluation but falls apart on live data, the overfitting post covers the diagnostic side of that problem in detail.
The amount by which leaky preprocessing inflates your scores depends on the problem. Sometimes it’s 0.3%. Sometimes it’s 4%. You won’t know which until you fix it and rerun, and by then you might have already committed to a model or presented numbers to someone.
Stratified K-Fold: When You Should Use It Instead
Standard k-fold splits randomly. That’s fine when your classes are balanced, but it creates a real problem with imbalanced datasets.
Say 5% of your examples are the positive class. With random splits, some folds might contain 2% positives and others 9%. The model’s performance in that fold is now measuring something slightly different in each run. Your cross-validation estimate gets noisy in a way that isn’t random noise about model quality but random noise about fold composition.
Stratified sampling fixes this by ensuring each fold has approximately the same class distribution as the full dataset.
from sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
scores = cross_val_score(pipeline, X, y, cv=skf, scoring='f1')
# each fold has roughly the same positive/negative ratioThe rule of thumb I use: if your dataset has any class imbalance at all (even mild, say 70/30), use StratifiedKFold. The overhead is zero and the downside of not using it is a noisier estimate for no reason.
When K-Fold Gives You a Dangerously Optimistic Score
There are two situations where standard k-fold will actively mislead you.
The first is time series data. If you’re predicting tomorrow’s stock price based on historical data, randomly shuffling and splitting into folds means your “training” data will include future dates relative to your “test” fold. You’d be using tomorrow to predict yesterday. The model looks brilliant. It’s cheating. Use TimeSeriesSplit from scikit-learn instead, which always trains on earlier data and tests on later data.
The second is grouped data. If you have multiple measurements from the same patient, user, or physical object, those rows aren’t independent. Random k-fold will put some rows from the same patient in training and others in the test fold. The model learns patient-specific patterns and then gets tested on that same patient’s other rows. You’re measuring memorization of individual subjects, not generalization. GroupKFold or StratifiedGroupKFold handles this by keeping all rows from each group in the same fold.
Both of these are cases where k-fold gives you a number that looks like a model evaluation score but is actually measuring something else entirely. The scikit-learn cross-validation documentation has a solid breakdown of every CV strategy and when each applies, which is worth bookmarking.
How Many Folds Should You Use?
The short answer: 5 for speed, 10 for slightly better estimates, and the difference is usually small enough not to matter.
But there’s a tension worth understanding. More folds means each training set is larger (more of your data gets used for training) and each test fold is smaller. Larger training sets mean more stable models. Smaller test folds mean noisier per-fold scores. Going from k=5 to k=10 usually improves the overall estimate a little, but gives you more variance across the individual fold scores.
Leave-one-out cross-validation (LOOCV) is the extreme case: k equals n, every point gets its turn as the test set. It’s nearly unbiased but computationally painful and tends to give high variance. It’s worth considering when your dataset is genuinely tiny (under a few hundred examples) and you need to squeeze every data point into both training and evaluation. For anything larger, 5 or 10 folds is the right call.
Cross-Validation for Hyperparameter Tuning
Here’s a trickier situation that catches people off guard.
You run cross-validation to evaluate five different values of a hyperparameter. You pick the best one. You report that CV score as your model’s expected performance. But this is also subtly optimistic, because you selected the hyperparameter based on what performed best across those specific folds. The reported score is the best of five estimates, not an unbiased estimate.
The correct way to handle this is nested cross-validation: an outer loop that provides the unbiased performance estimate, and an inner loop that tunes hyperparameters. GridSearchCV or RandomizedSearchCV handles the inner loop, and you wrap that in another cross_val_score call for the outer.
from sklearn.model_selection import GridSearchCV, cross_val_score
param_grid = {'clf__n_estimators': [50, 100, 200], 'clf__max_depth': [3, 5, None]}
inner_cv = StratifiedKFold(n_splits=3, shuffle=True, random_state=42)
outer_cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
grid_search = GridSearchCV(pipeline, param_grid, cv=inner_cv, scoring='f1')
# outer CV gives the honest estimate
nested_scores = cross_val_score(grid_search, X, y, cv=outer_cv, scoring='f1')
print(f"Nested CV estimate: {nested_scores.mean():.3f} (+/- {nested_scores.std():.3f})")This is more expensive computationally. For many practical problems the optimism introduced by non-nested tuning is small enough not to matter. But if you’re comparing models or reporting results formally, the nested approach is the one you can actually defend.
Actually, let me be more precise about that. The gap between nested and non-nested CV scores is usually small on large datasets where the inner CV has plenty of data to tune on. It gets meaningful when your dataset is small, your hyperparameter search is wide, or both. If you’re on a small dataset and doing broad search, use nested CV.
What This Post Didn’t Cover
I didn’t go into cross-validation for regression versus classification in terms of which scoring metrics to use inside the CV loop. That’s an important topic but adds enough length to belong in a separate post on model evaluation metrics.
I also skipped repeated k-fold, where you run the entire k-fold procedure multiple times with different random seeds and average all the results. It’s worth knowing about for high-stakes evaluations where you want a very tight confidence interval on your estimate.
FAQ
What is k-fold cross-validation and why is it used?
K-fold cross-validation splits your dataset into k equal groups. The model trains k times, each time using a different fold as the test set and the rest as training data. Scores are averaged across all k runs. It’s used because a single train-test split can give a noisy performance estimate, especially on small datasets. K-fold gives a more reliable estimate by testing the model across multiple different data slices.
What is the difference between k-fold and stratified k-fold cross-validation?
Standard k-fold splits data randomly without considering class labels. Stratified k-fold ensures each fold contains approximately the same proportion of each class as the full dataset. You should use stratified k-fold whenever your classes are imbalanced, meaning one class is more common than another, because random splits can create folds with very different class distributions that make your evaluation estimates noisy.
How does cross-validation prevent overfitting?
Cross-validation doesn’t prevent overfitting during training it detects it during evaluation. If a model overfits badly, its score on held-out test folds will be consistently lower than on training data. That gap, visible across multiple folds, is your signal that the model isn’t generalizing. You’d then address the overfitting through regularization, simplifying the model, or getting more data. Cross-validation is a diagnostic tool, not a cure.
The thing I’d want you to take away from this is cross-validation done carelessly (preprocessing outside the pipeline, no stratification, wrong variant for your data type) can give you numbers that feel solid but are quietly misleading. Done correctly, it’s genuinely one of the most useful tools in the whole model development process.
There’s still an open question I haven’t seen a satisfying answer to: at what dataset size does a single holdout set become just as reliable as k-fold? The folk wisdom says cross-validation is for small data and a simple split is fine for large data, but I’ve never seen a principled threshold that holds across problem types. If you have a reference, I’d genuinely like to know.

